ICML 2013 Tutorial: Afternoon (14:00-17:30)
Music information research is gaining a lot of attention after 2000 when the general public started listening to music on computers in daily life. It is widely known as an important research field, and new researchers are continually joining the field worldwide. Academically, one of the reasons many researchers are involved in this field is that the essential unresolved issue is the understanding of complex musical audio signals that convey content by forming a temporal structure while multiple sounds are interrelated. Additionally, there are still appealing unresolved issues that have not been touched yet, and the field is a treasure trove of research topics that could be tackled with state-of-the-art machine learning techniques.
This tutorial is intended for an audience interested in the application of machine learning techniques to such music domains. Audience members who are not familiar with music information research are welcome, and researchers working on music technologies are likely to find something new to study.
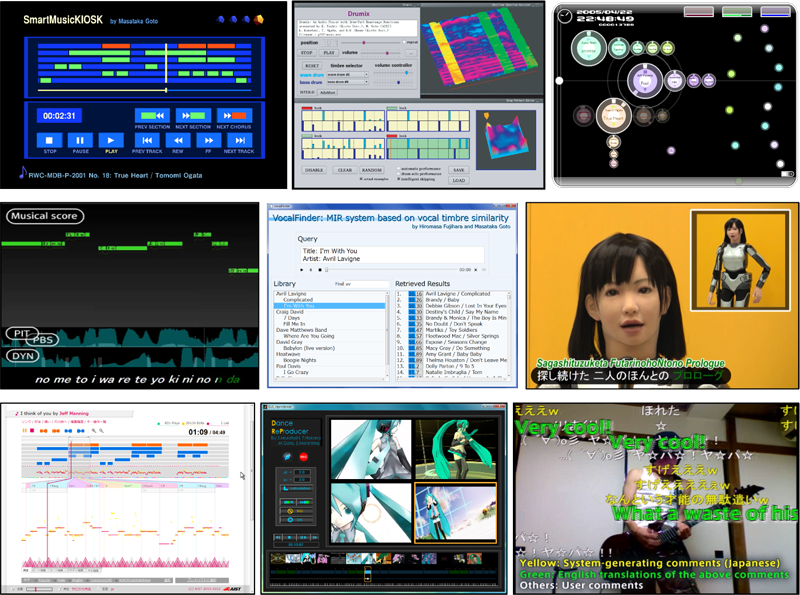
First, the tutorial serves as a showcase of music information research. The audience can enjoy and study many state-of-the-art demonstrations of music information research based on signal processing and machine learning. This tutorial highlights timely topics such as active music listening interfaces, singing information processing systems, web-related music technologies, crowdsourcing, and consumer-generated media (CGM).
Second, this tutorial explains the music technologies behind the demonstrations. The audience can learn how to analyze and understand musical audio signals, process singing voices, and model polyphonic sound mixtures. As a new approach to advanced music modeling, this tutorial introduces unsupervised music understanding based on nonparametric Bayesian models.
Third, this tutorial provides a practical guide to getting started in music information research. The audience can try available research tools such as music feature extraction, machine learning, and music editors. Music databases and corpora are then introduced. As a hint towards research topics, this tutorial also discusses open problems and grand challenges that the audience members are encouraged to tackle.
In the future, music technologies, together with image, video, and speech technologies, are expected to contribute toward all-around media content technologies based on machine learning.
Masataka Goto (http://staff.aist.go.jp/m.goto/) received the Doctor of Engineering degree from Waseda University in 1998. He is currently a Prime Senior Researcher and the Leader of the Media Interaction Group at the National Institute of Advanced Industrial Science and Technology (AIST), Japan. In 1992 he was one of the first to start work on automatic music understanding, and has since been at the forefront of research in music technologies and music interfaces based on those technologies. Since 1998 he has also worked on speech recognition interfaces, and since 2006 he has overseen the development of web services based on content analysis and crowdsourcing (http://songle.jp and http://en.podcastle.jp). He serves concurrently as a Visiting Professor at the Institute of Statistical Mathematics, an Associate Professor (Cooperative Graduate School Program) in the Graduate School of Systems and Information Engineering, University of Tsukuba, and a Project Manager of the Exploratory IT Human Resources Project (MITOH Program) run by the Information Technology Promotion Agency (IPA).
Over the past 21 years, Masataka Goto has published more than 190 papers in refereed journals and international conferences and has received 33 awards, including several best paper awards, best presentation awards, and the Commendation for Science and Technology by the Minister of Education, Culture, Sports, Science and Technology (Young Scientists' Prize). He has served as a committee member of over 80 scientific societies and conferences and was the Chair of the IPSJ (Information Processing Society of Japan) Special Interest Group on Music and Computer (SIGMUS) in 2007 and 2008 and the General Chair of the 10th International Society for Music Information Retrieval Conference (ISMIR 2009). In 2011, as the Research Director he began a 5-year research project (OngaCREST Project) on music technologies, a project funded by the Japan Science and Technology Agency (CREST, JST).
Google scholar h-index=36: http://scholar.google.com/citations?user=4JJCMq8AAAAJ&hl=en
Kazuyoshi Yoshii (http://staff.aist.go.jp/k.yoshii/) received the PhD degree in Informatics from Kyoto University, Japan in 2008. He is currently a Senior Researcher at the National Institute of Advanced Industrial Science and Technology (AIST), Japan. He is well known in the field of music information processing for his knowledge of machine learning and Bayesian inference. He is also one of the pioneers who have applied the paradigm of Bayesian nonparametrics to music information processing. In particular, he is the first researcher to develop a nonparametric Bayesian multipitch analyzer.
He is the first author of more than 15 refereed conference papers and 3 refereed journal papers of IEEE Transactions on Audio, Speech, and Language Processing. He has received 15 awards, including the IPSJ Yamashita SIG Research Award and the Best-in-Class Award of MIREX 2005. His current research interests include probabilistic music modeling and blind source separation based on Bayesian nonparametrics. He is a member of the IEEE, Information Processing Society of Japan (IPSJ), and Institute of Electronics, Information and Communication Engineers (IEICE).
Google scholar h-index=11: http://scholar.google.com/citations?user=QaNTClUAAAAJ&hl=en
Other relevant references are shown in the tutorial slides.
[1] M. Goto: Active Music Listening Interfaces Based on Signal Processing, Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2007), pp.1441-1444, 2007.
![]()
[2] M. Goto: A Chorus-Section Detection Method for Musical Audio Signals and Its Application to a Music Listening Station, IEEE Transactions on Audio, Speech, and Language Processing, Vol.14, No.5, pp.1783-1794, 2006.
![]()
[3] M. Goto: Music Listening in the Future: Augmented Music-Understanding Interfaces and Crowd Music Listening, Proceedings of the AES 42nd International Conference on Semantic Audio, pp.21-30, 2011. (Invited Paper)
![]()
[4] M. Goto, T. Saitou, T. Nakano, and H. Fujihara: Singing Information Processing Based on Singing Voice Modeling, Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2010), pp.5506-5509, 2010.
![]()
[5] Masataka Goto, Tomoyasu Nakano, Shuuji Kajita, Yosuke Matsusaka, Shin'ichiro Nakaoka, and Kazuhito Yokoi:
VocaListener and VocaWatcher: Imitating a Human Singer by Using Signal Processing,
Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2012), pp.5393-5396, 2012.
![]()
[6] M. Goto, J. Ogata, K. Yoshii, H. Fujihara, M. Mauch and T. Nakano: PodCastle and Songle: Crowdsourcing-Based Web Services for Retrieval and Browsing of Speech and Music Content, Proceedings of the First International Workshop on Crowdsourcing Web Search (CrowdSearch 2012), pp.36-41, 2012.
![]()
[7] M. Goto, K. Yoshii, H. Fujihara, M. Mauch, and T. Nakano: Songle: A Web Service for Active Music Listening Improved by User Contributions, Proceedings of the 12th International Society for Music Information Retrieval Conference (ISMIR 2011), pp.311-316, 2011.
![]()
![]()
[8] Masataka Goto: Grand Challenges in Music Information Research, In Meinard Muller, Masataka Goto, and Markus Schedl, editors, Dagstuhl Follow-Ups: Multimodal Music Processing, pp.217-225, Dagstuhl Publishing, 2012.
![]()
[9] K. Yoshii and M. Goto: Unsupervised Music Understanding Based on Nonparametric Bayesian Models, Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2012), pp.5353-5356, 2012.
![]()
[10] K. Yoshii and M. Goto: A Nonparametric Bayesian Multipitch Analyzer Based on Infinite Latent Harmonic Allocation, IEEE Transactions on Audio, Speech, and Language Processing, Vol.20, No.3, pp.717-730, 2012.
![]()
[11] K. Yoshii and M. Goto: A Vocabulary-Free Infinity-Gram Model for Nonparametric Bayesian Chord Progression Analysis, Proceedings of the 12th International Society for Music Information Retrieval Conference (ISMIR 2011), pp.645-650, 2011.
![]()
[12] K. Yoshii and M. Goto: Infinite Latent Harmonic Allocation: A Nonparametric Bayesian Approach to Multipitch Analysis, Proceedings of the 11th International Society for Music Information Retrieval Conference (ISMIR 2010), pp.309-314, 2010.
![]()
![]()
[13] K. Yoshii and M. Goto, et al.: An Efficient Hybrid Music Recommender System Using an Incrementally Trainable Probabilistic Generative Model, IEEE Transactions on Audio, Speech, and Language Processing, Vol.16, No.2, pp.435-447, 2008.
![]()
[14] K. Yoshii, M. Goto, and H. G. Okuno: Drum Sound Recognition for Polyphonic Audio Signals by Adaptation and Matching of Spectrogram Templates with Harmonic Structure Suppression, IEEE Transactions on Audio, Speech, and Language Processing, Vol.15, No.1, pp.333-345, 2007.
![]()