![]() Extraction of local invariant features by GPU computing
Extraction of local invariant features by GPU computing
Local invariant features have been widely used as fundamental elements for image matching and object recognition. Although dense sampling of local features is useful in achieving an improved performance in image matching and object recognition, it results in increased computational costs for feature extraction. The purpose of this paper is to develop fast computational techniques for extracting local invariant features through the use of a graphics processing unit (GPU). In particular, we consider an algorithm that uses multiresolutional orientation maps to calculate local descriptors consisting of the histograms of gradient orientations. By using multiresolutional orientation maps and applying Gaussian filters to them, we can obtain voting values for the histograms for all the pixels in a scale space pyramid. We point out that the use of orientation maps has two advantages in GPU computing. First, it improves the efficiency of parallel computing by reducing the number of memory access conflicts in the overlaps among local regions, and secondly it utilizes a fast implementation of Gaussian filters that permits the use of shared memory for the many convolution operations required for orientation maps. We conclude with experimental results that demonstrate the usefulness of multiresolutional orientation maps for fast feature extraction.
The following images, "Tour de France" and "Graffiti", were used in the experiments to measure the computational times for extracting local invariant features. The top row shows the original images and the bottom row represents the local regions as the yellow rectangles in which the local descriptors are calculated. The resolutions of images were 720x480 and 320x240.



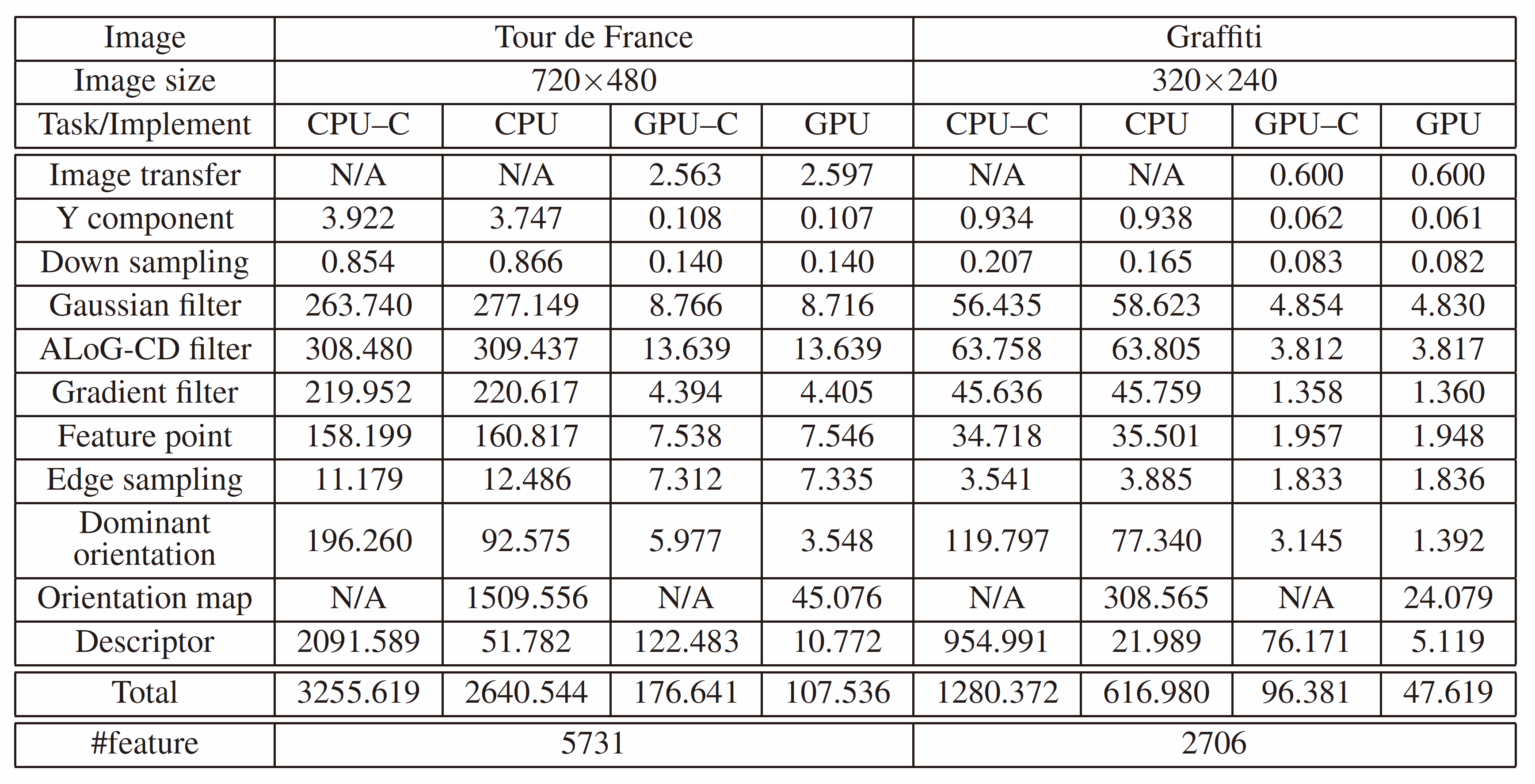
The computational times for the tasks to extract the local invarinat features are listed blow. There are 4 implementations in this table: CPU-C and GPU-C stand for the CPU and GPU implementations of the conventional method which does not used the orientation maps to calculate the descriptors. CPU and GPU represent the CPU and GPU implementations of the method using the orientation maps. The CPU was an Intel Quadcore Xeon 3.16GHz and the GPU was a NVIDIA GeForce GTX280.
By comparing the computational times for “Dominant orientation”, “Orientation map” and “Descriptor” among the implementations, we can see that both the introduction of orientation maps and the use of the GPU are very effective in terms of fast feature extraction. Although the effectiveness depends on the resolution of the image and the contents of the scene, the method is more than 30 times as fast as the conventional method on the CPU and about 2 times as fast as the conventional method on the GPU.
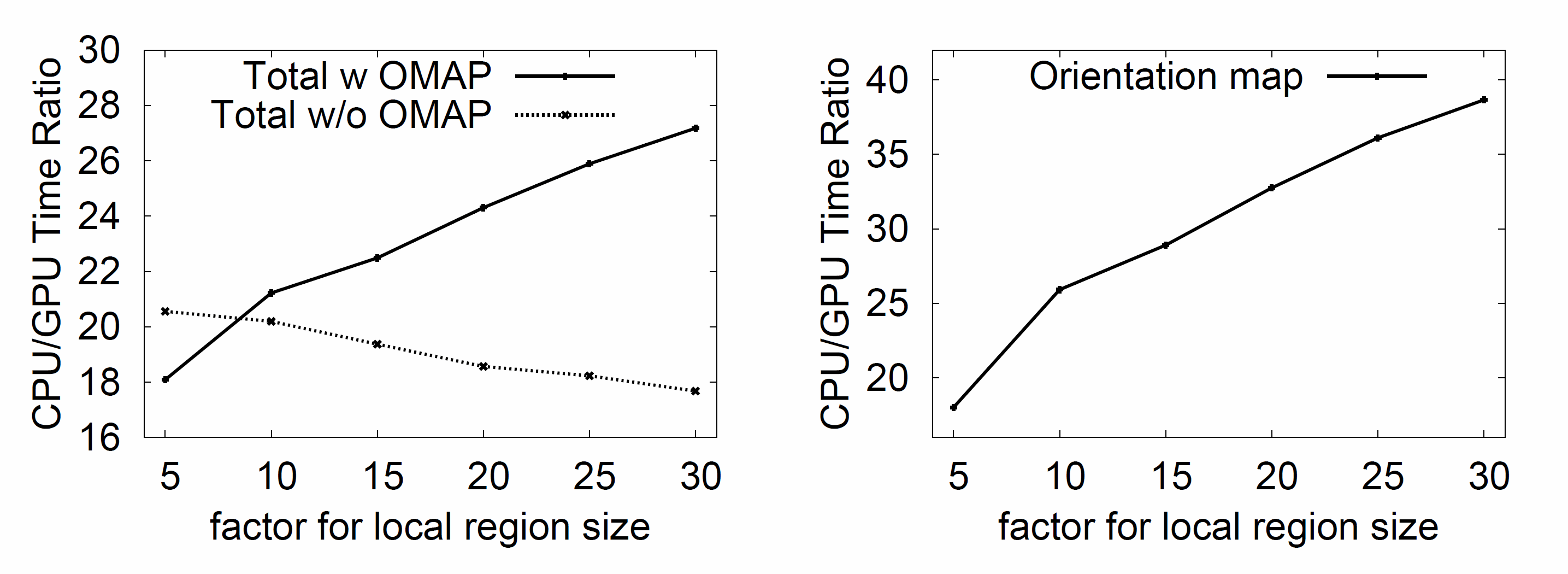
The following graphs show the efficiency of the parallel computation in feature extraction of the image "Tour de France" . The horizontal axis represents the factor which is proportaional to the sizes of local regions. The vertical axis show the ratio between the computational times on the CPU and the GPU. The ratio of the computational times reflects the efficiency of parallel computing because the computational cost is the same for both the CPU and the GPU. We can change the area of the overlaps among local regions by altering the factor of the horizontal axis. This means that the computational dependency among local regions varies with the factor. The use of a smaller factor reduces the multiple computation for the histograms and the number of memory access conflicts in the overlaps, which increases the efficiency of the parallel computing.
As we can see from the graph on the left, when no orientation maps were used, the efficiency of parallel computing fell as the factor was increased. On the other hand, the efficiency was obviously maintained when orientation maps were used. One reason for this improvement is the reduction in the multiple computation for the histograms and the number of memory access conflicts in the overlaps, and another one is the fast implementation of the Gaussian filters for the multiresolutional orientation maps. The graph on the right shows the advantage of the parallel implementation of the Gaussian filters with the shared memory in comparison with the CPU-based implementation. Because the areas of the local regions increase as the factor is increased, we need Gaussian filters with larger scales, which yield a large number of convolution operations. However, no degradation of the efficiency of the parallel computation was observed as a result of data reuse in the shared memory. Similar results were obtained for the Graffiti image.
In summary, we have shown that the use of multiresolutional orientation maps for calculating the descriptors has two advantages in GPU computing: an improvement in the efficiency of parallel computing as a result of a reduction in the multiple computation for the histograms and the number of memory access conflicts in the overlaps among local regions, and the utilization of the fast implementation of Gaussian filters using the shared memory for large numbers of convolution operations for orientation maps.