Web情報取得MZ PlatformでWeb上の情報を取得して処理するアプリケーションを作成したので紹介します。 さらに、取得したWeb上の情報とセンサデータを統合する例については、 こちらをご覧ください。 概要MZ Platformでは、バージョン2.7から「ネットワーク接続」コンポーネントを提供しています。 ネットワーク接続コンポーネントを用いると、URL指定でWeb上に存在するデータを文字列として取得し、 そのデータを用いた処理を記述することが可能です。 ここでは、Web上の気象データを文字列として取得して、 その文字列からテーブルとグラフを作成するMZアプリについて説明します。 下図がそのMZアプリの画面イメージです。 
また、文字列からテーブルを抽出する処理では、スクリプト実行コンポーネントを利用しています。 取得した文字列からのデータ抽出は、ビルダー上で記述しようとすると複雑な場合が多いですが、 処理がサイトの記述方法に依存するため、 毎回ソースコードを書いてコンポーネントを作成するのは現実的ではありません。 スクリプト実行コンポーネントを用いることで、 複雑な処理をソースコードレベルで記述し、状況に応じて簡単に修正することが可能になります。 対象例:気象庁のアメダス(表形式)ここでは、Web情報の例として気象庁 のアメダスを対象にしました。 Webブラウザから閲覧する場合は、各地点を選択すると各種の気象データが表形式で表示されます。 ここでは、つくば・水戸・東京の3地点について、本日と昨日のデータを取得します。 
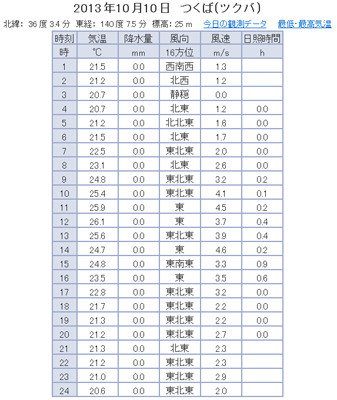
下図がつくばのアメダス(表形式)をWebブラウザで表示したときの様子です。
左が本日、右が昨日のデータで、抽出したい表の部分だけを抜き出してあります。URLはそれぞれ、 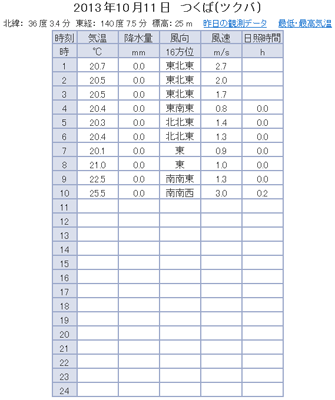
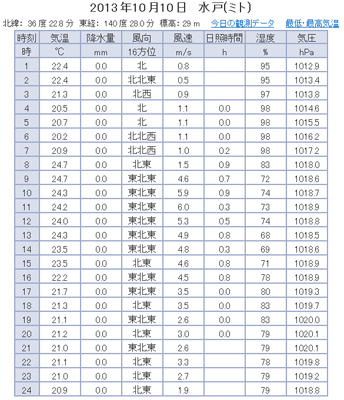
下図が水戸のデータです。URLはそれぞれ、 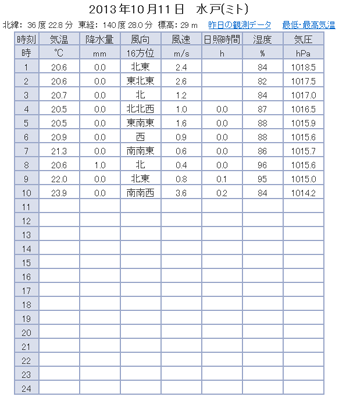
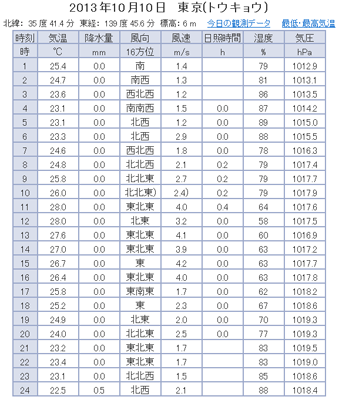
下図が東京のデータです。URLはそれぞれ、 
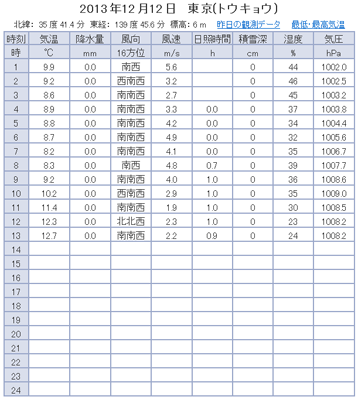
以上のデータから、つくばの気温および水戸と東京の気圧を抽出してグラフ化したのが、 概要で示した図になります。 (2013/12/12追記) ふと気付きましたが、下図のように 雪が降る季節になると上記の表は列が一つ増え、 雪が降らない季節になると元に戻るようです。 これで問題となるのは、気圧の列の位置が一つ増えることです。 気温は列位置が変わらないので、影響ありません。 これによって、最後のグラフ作成のところで、 列位置を数値固定で指定していたところを季節の変化に応じて値を変えることにしました。 
Web上の文字列取得URL指定でWeb上の文字列データを取得するために、ネットワーク接続コンポーネントを用います。 使い方は簡単で、下図のように「URL指定でデータを文字列として取得する」を呼び出すだけです。 引数には文字列でURLを指定します。ここでは、1引数のファンクションとして処理を記述しています。 Webに接続していない場合などに呼び出すとエラーが発生するので、 エラー処理のダイアログ表示も記述しています。 
このファンクションを実行すると、下図のようなHTML形式の文字列データが得られます。 
このままだとただの文字列なので、必要な情報を抽出する処理が必要です。 テーブル抽出スクリプトWeb上の文字列から必要な情報を抽出する処理は、対象のWebページの構造と必要な情報の種類によって変わります。 ここで対象とする情報は、HTMLのテーブルの中に含まれているので、文字列からテーブルを抽出します。 また、気象庁のアメダス(表形式)のHTMLソースを見ると、 対象となるテーブルには特定のIDが割り振られていることがわかりました。 そこで、ここでは特定のIDを持つHTMLのテーブルをMZのテーブルデータとして抽出することにします。 文字列からテーブルを抽出する処理は、ビルダー上でも記述できますが、 複雑な処理を記述するには不向きなため、 ここではスクリプト実行コンポーネントを用いて、 BeanShell 形式でJavaのソースコードを書くように処理を記述します。 下記がそのスクリプトです。 Javaと同様にimport文で特定のクラスを呼べるようにしますが、 クラスを作成したりメソッドを宣言することなく、実行したい順に上から文を書いていくことができます。 ここでは、HTML文字列から正規表現で文字列を抽出することで、テーブルを作成しています。
import java.util.regex.Pattern;
import java.util.regex.Matcher;
import jp.go.aist.dmrc.platform.util.PFObjectTable;
import jp.go.aist.dmrc.platform.util.PFObjectList;
PFObjectTable table = new PFObjectTable(); // 抽出結果となる空のテーブルデータを作成
String regex_table = "<table(.*?)>(.*?)</table>"; // テーブル文字列を指す正規表現
Pattern pattern_table = Pattern.compile(regex_table,Pattern.DOTALL);
Matcher match_table = pattern_table.matcher(html); // 対象文字列全体からテーブルを検索
// ※対象文字列全体を指す変数 html はスクリプト内で宣言されず、外から与えられる(後述)
String regex_attr = "id=\"(.*?)\""; // ID文字列を指す正規表現
Pattern pattern_attr = Pattern.compile(regex_attr, Pattern.DOTALL);
Matcher match_attr;
String html_table = "";
String html_attr = "";
while (match_table.find()) { // 検索されたテーブル文字列に関するループ
html_attr = match_table.group(1); // テーブルの属性文字列
match_attr = pattern_attr.matcher(html_attr); // 属性文字列からID文字列を検索
if (match_attr.find()) { // ID文字列が存在
String html_id = match_attr.group(1); // ID文字列
if (html_id.equals(id)) // ID文字列が対象ID文字列に一致した場合
html_table = match_table.group(2); // テーブルのデータ部分の文字列
// ※対象ID文字列を指す変数 id はスクリプト内で宣言されず、外から与えられる(後述)
}
}
String regex_row = "<tr.*?>(.*?)</tr>"; // テーブルの行を指す正規表現
Pattern pattern_row = Pattern.compile(regex_row,Pattern.DOTALL);
Matcher match_row = pattern_row.matcher(html_table); // テーブルデータの文字列から行を検索
String regex_cell = "<td.*?>(.*?)</td>"; // テーブルのセルを指す正規表現
Pattern pattern_cell = Pattern.compile(regex_cell,Pattern.DOTALL);
Matcher match_cell;
PFObjectList list = new PFObjectList(); // 行データのリスト
int num_col = 0;
while (match_row.find()){ // 検索された行文字列に関するループ
PFObjectList list_cell = new PFObjectList(); // 行ごとにセルのリストを作成
match_cell = pattern_cell.matcher(match_row.group(1)); // 行文字列からセル文字列を検索
while (match_cell.find()) { // 検索されたセル文字列に関するループ
String cell = match_cell.group(1); // セル文字列
cell = cell.trim(); // 前後の空白文字等を除去
if (cell.equals(" ")) cell = ""; // 空白を指す特殊文字は空文字に置換
list_cell.add(cell); // セルのリストに文字列追加
}
int num = list_cell.size();
if (num>num_col) num_col = num; // セルのリストの要素数は列数になる
list.add(list_cell); // 行データのリストにセルのリストを追加
}
for (int i=0; i<num_col; i++) {
table.addColumn("",String.class); // テーブルに列数だけ文字列型の列を追加
}
for (int i=0; i<list.size(); i++) {
PFObjectList list_cell = (PFObjectList) list.get(i); // 行のリストからセルのリストを取得
for (int j=list_cell.size(); j<num_col; j++) {
list_cell.add(""); // 列数に満たなければ空文字を追加
}
table.addRow(list_cell); // セルのリストを行データとしてテーブルに追加
}
return table; // 抽出結果のテーブルを返す
以上のようなスクリプトを、スクリプト実行コンポーネントの属性StoredScriptに設定し、 属性Languageをjavaとし、ビルダー上で下図のように処理を記述します。 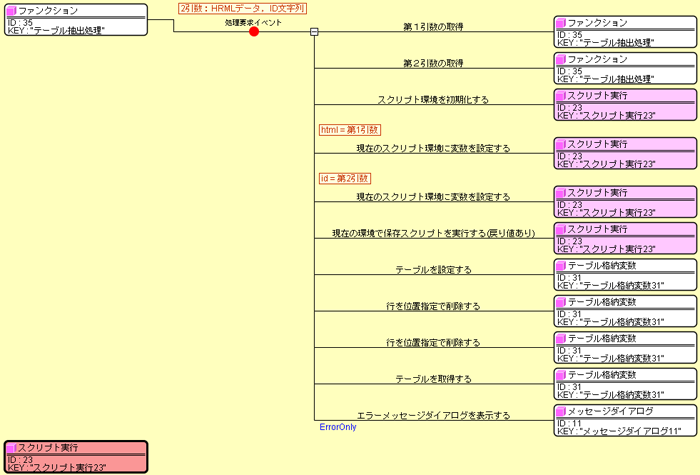
スクリプト実行コンポーネントに対して、まず環境を初期化し、必要な変数を設定して、 最後に保存スクリプトを実行します。 ここでは、対象とするHTML文字列データを変数htmlとし、 抽出したいテーブルのID文字列を変数idとして指定します。 このように、環境を初期化してからスクリプトを実行するまでの間に、 必要な変数の値を外部から指定することができます。 ここでは、スクリプトの戻り値でテーブルを返すので、 それをテーブル格納変数に設定してさらに処理をしています。 前述のデータ例を見ればわかるように、必ずヘッダに相当する2行が最初に存在するので、 ここでは先頭の2行を常に削除しています。 グラフ作成最後に、抽出したテーブルデータを加工してグラフを作成します。 ここでは、下図に示すつくばの気温に関する処理でその流れを説明します。 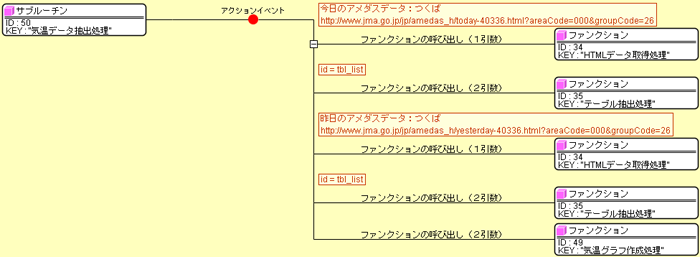
URLを指定して今日と昨日のデータを文字列として取得し、 取得した文字列とIDで2つのテーブルを抽出します。 続いて、下図に示すように抽出した2つのテーブルからグラフ用のテーブルデータを作成します。 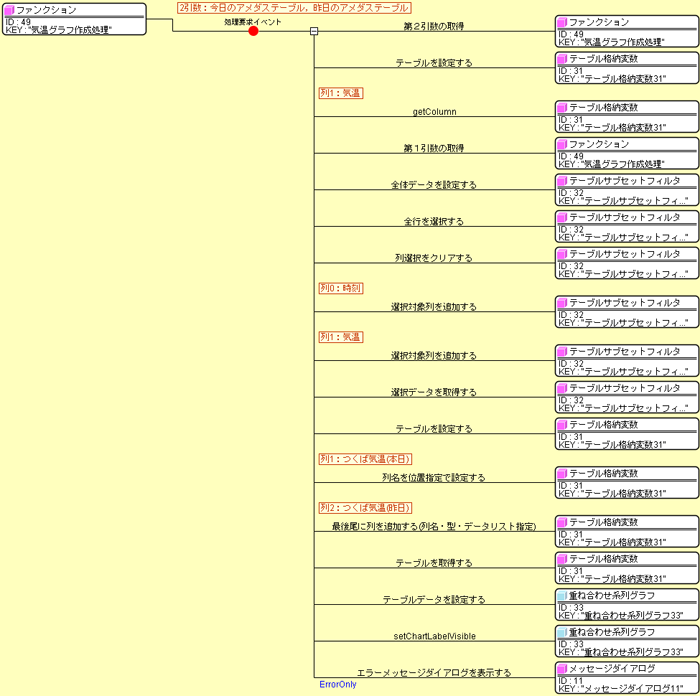
おおまかに説明すると、今日のテーブルから時刻と気温の列だけ抜き出したテーブルを作成し、 そのテーブルに昨日のテーブルの気温の列を抜き出して追加すれば、グラフ用のテーブルとなります。 この例では、気温と気圧を同時に表示するので、重ね合わせ系列グラフを用いて表示しています。 ここでは省略しますが、気圧のテーブルは水戸と東京それぞれの今日と昨日のデータがあるので、 4つのテーブルから同様の処理でグラフ用のテーブルを作成します。 (2013/12/12追記) 上記の表の説明で書いたように、気圧の列位置は季節によって変わってしまうので、 固定値ではなくテーブルの最終列位置として指定することで変化に対応しました。
作成日 2013-10-11
最終更新日 2013-12-12
|