日本語構造解析日本語の形態素解析器MeCab と同じく係り受け解析器CaboCha を呼び出すアプリケーション(Windows版)を作成しました。 それぞれの機能の詳細についてはリンク先をご覧ください。 準備としてそれぞれのリンク先からWindows版のバイナリパッケージを入手する必要があります。 概要MeCabとCaboChaのEXEファイルを外部プログラム通信コンポーネントから起動して、 結果をテキストエリアに表示し、さらにMZのテーブルに変換します。 対象とする文章の入力はテキストエリアで指定します。 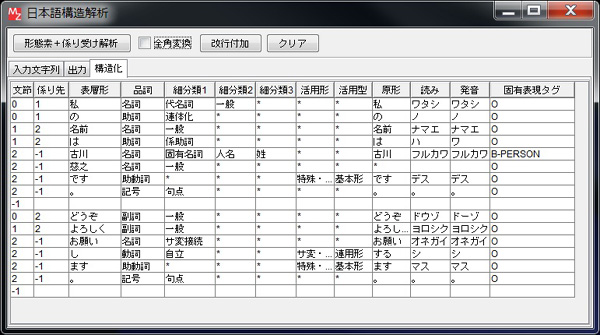
コマンドラインアプリケーション実行のGUI化バージョンまたは環境の問題かもしれませんが、CaboChaはコマンドラインでの実行がうまくいかなかったので、 多少工夫しました。エラー内容を見るとMeCabを内部的に呼び出すところで失敗しているようだったので、 MeCabを実行して出力結果を一時的にファイル保存し、CaboChaをそのファイル指定で起動するようにして回避しました。 それぞれのコマンドは次のようになります。 (実行用のパス)mecab.exe -r (設定用のパス)mecabrc -o outfile.txt MeCabは上記のコマンドをWindowsのコマンドプロンプトで入力すると、 標準入力から文字列入力を受け付けるようになります。 その状態で一文ごとに改行を入れて、最後にCtrl+Cを入力して終了します。 結果は現在のフォルダにoutfile.txtファイルとして出力されます。 例として下図のように入力します。 
作成されたoutfile.txtファイルの中身は下図のようになります。 これが形態素に分割された状態です。 
続いてCaboChaを実行します。 (実行用のパス)cabocha.exe -f1 -I1 -r (設定用のパス)cabocharc < outfile.txt CaboCha は上記のコマンドをWindowsのコマンドプロンプトで入力すると、 標準出力に結果が出力されます。形態素をまとめた文節の情報が追加され、 文節の係り受け関係が追加されます。また、固有表現タグが追加されています。 -f1というオプションで、このような計算機処理用のフォーマットで出力されるようです。 また、-I1というオプションで、MeCabを呼び出さずその処理結果を入力に使うようです。 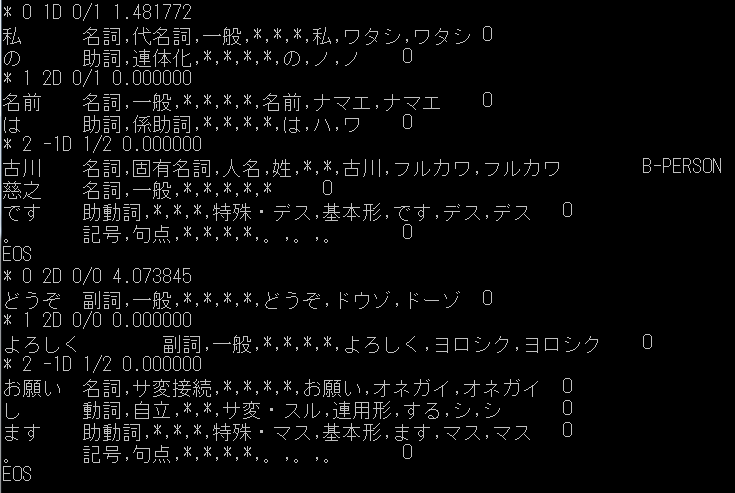
このアプリケーションでは、このような処理をGUIから実行して結果を表示します。 「入力文字列」タブのテキストエリアに解析したい文章を入力して、「形態素+係り受け解析」ボタンを押します。 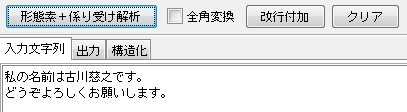
すると、実行結果が「出力」タブのテキストエリアに下図のように出力されます。 これは前述のcabocha.exeを呼び出した最後の出力結果に対応します。 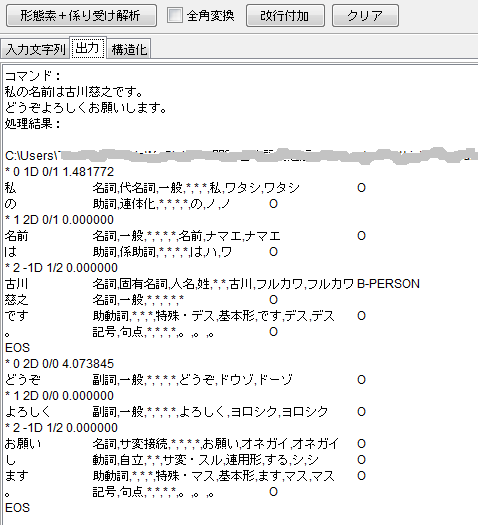
このような処理の記述について、下図を用いて説明します。 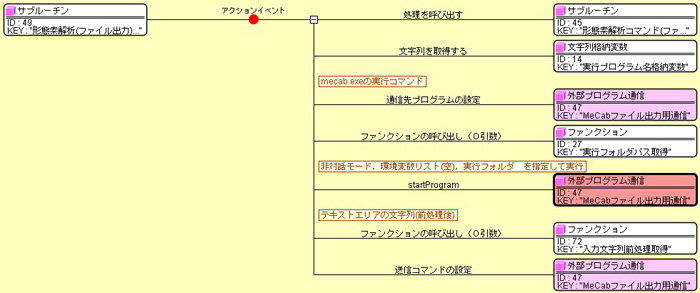
一般的にコマンドラインアプリケーションの起動では、外部プログラム通信を使います。 「通信先プログラムの設定」メソッドで、前述のコマンドを設定し、 「startProgram」メソッドで起動します。 このとき、指定したい引数の種類によって使うメソッドを変える必要があります。 ここでは、非対話モードと実行フォルダを指定する必要があったので、3引数のメソッドを選択しました。 続いて、MeCabは起動した後に入力文字列を渡す必要がありますので、 「送信コマンドの設定」メソッドでテキストエリアの文字列を渡しています。 なお、このように起動後に送信コマンドを送るとき、対話モードで起動する必要がある場合と、 非対話モードで起動する必要がある場合の両方がありえるようです。 いろいろ調査した結果、コマンドライン上での使い方が同一でも、 外部プログラム通信コンポーネントを介すと違いが出てくることがわかっています。 そのため、一概にどういう場合に対話モードにすると明確に言えず、 試してみて動く方でお使いいただくしかありません。 今回は試した結果、非対話モードで動作したということです。 これは今後の課題とさせていただきます。 さて、続いてコマンド送信後の処理を下図を用いて説明します。 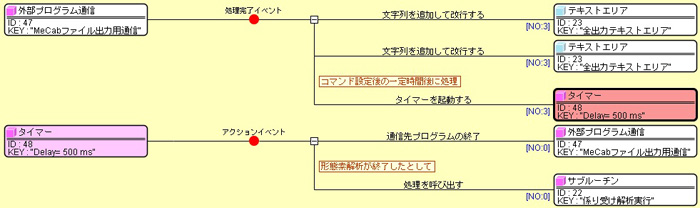
コマンド送信が完了すると、 外部プログラム通信コンポーネントから処理完了イベントが発生します。 ここでは入力文字列をMeCabに渡して形態素解析の結果をファイルに出力してもらっていますので、 それが終わったタイミングでMeCabを終了して次の処理に移りたいところです。 このアプリケーションでは、タイマーコンポーネントを使って0.5秒後に外部プログラム通信の 「通信先プログラムの終了」メソッドを呼び出します。 0.5秒という数字はなんとなく使ってみて大丈夫な時間を選びました。 MeCabを終了させたら次はCaboChaの実行に移ります。 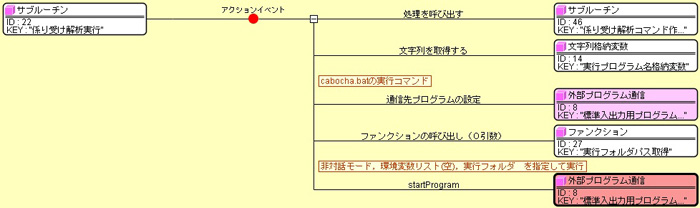
MeCabと同様に前述のコマンドを実行して完了といけばいいのですが、 ここでも問題が発生しました。前述のコマンドでは、ファイルの内容を入力として渡す 「リダイレクト」を用いています。 残念ながら、この機能は外部プログラム通信コンポーネントでは利用できません。 今回は前述のコマンドを実行するBATファイルを作成して、それを実行することで回避しました。 CaboChaの実行では実行後の送信コマンドは不要なので、 処理が完了したあとのイベント発生で結果をテキストエリアに出力しています。 入力の前処理CaboChaは入力文章の一行に関する係り受け解析を前提にしているようなので、 文末に改行を付加して文末の文節の係り先を-1として文の終わりを明確にすることにします。 テキストエリアに入力された文章に対して、「。」が存在したらその後ろに改行を付加する処理を、 下図のように記述しました。 この処理では、テキストエリアの文字列を変数に入れて後方から「。」をWhileループで探索して、 発見したら後ろに改行を付加するようになっています。 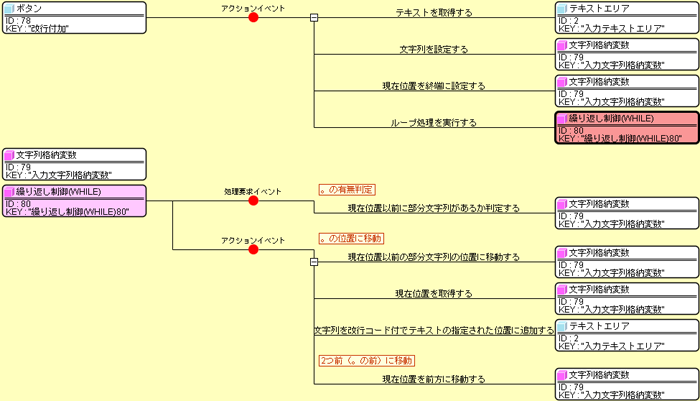
この処理によって、改行なしで下図のように入力されている状態で、 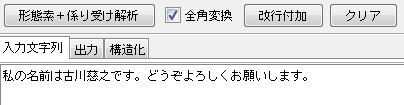
「改行付加」ボタンを押すと「。」の後ろで改行されます。 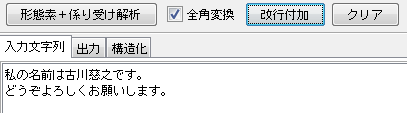
出力テキストのテーブル化このアプリケーションでは、文字列として得られた解析結果をMZのテーブルに変換します。 結果の例は概要の図に示した通りです。 対象とする文字列は前掲の図の通りで、下記のような構造となっています。 先頭に*が付くと文節行で、そのあとに形態素行が続き、 その構成が繰り返されて行の最後を示すEOSが出現するという感じです。 複数文が含まれていればその繰り返しとなります。
また、各行は下記のような構造になっています。
ただし、文末の文節は係り先番号が-1となります。 あとはこの構造に従って必要なデータを取り出してテーブルを作成すればよいのですが、 全部書くとかなり長くなるので、最初のところだけ紹介するにとどめます。 下図は、処理結果の文字列を設定する変数で、文字列が設定されてイベントが発生したときの処理を示しています。 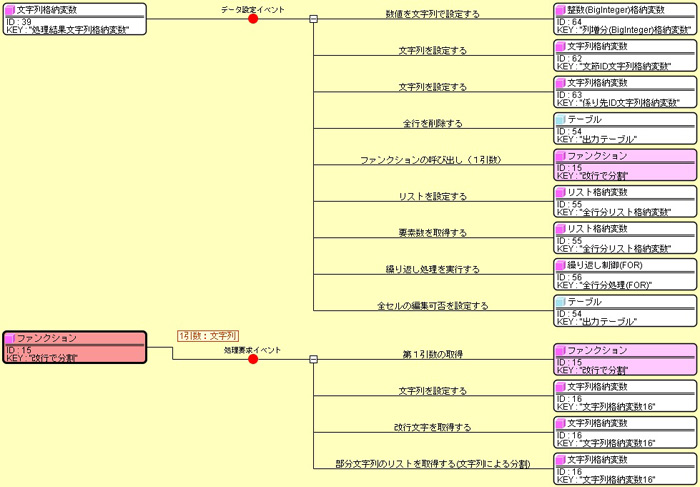
変換処理は主に文字列格納変数を使用して、特定の文字列で分割した部分文字列のリスト作成と、 部分文字列の位置を探索して必要なデータを取り出すことの組み合わせで実現しています。 ここでは、最初に改行文字で全体を分割した行ごとの部分文字列リストを取得して、 それをリスト格納変数に入れて各要素をFORループで処理していることを示しています。 FORループの中身は省略しますが、要素がEOSなら行末として、先頭文字が*なら文節として、 それ以外なら形態素行として処理を分岐しています。
作成日 2012-09-26
最終更新日 2012-09-26
|