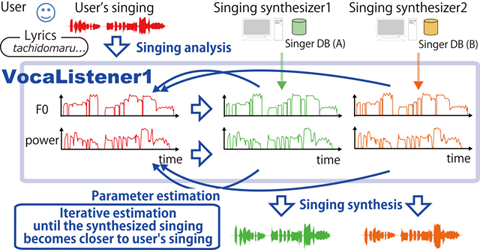
Figure 1. Overview of VocaListener
[ English | Japanese ]
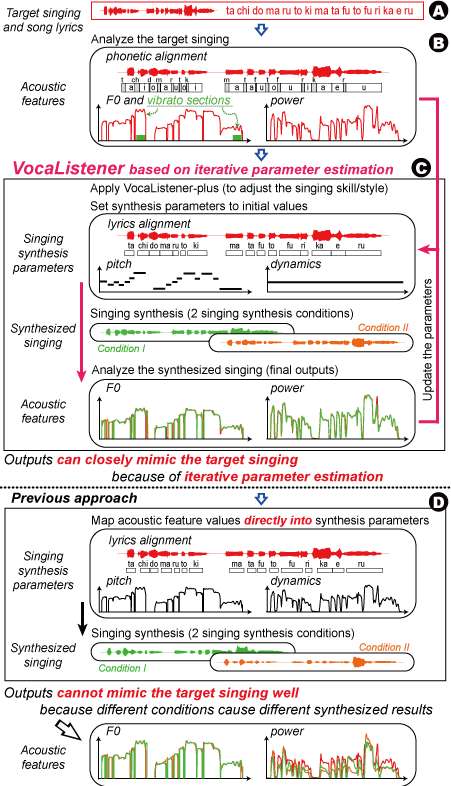
This paper presents a singing synthesis system, VocaListener, that automatically estimates parameters for singing synthesis from a user's singing voice with the help of song lyrics. Although there is a method to estimate singing synthesis parameters of pitch (F0) and dynamics (power) from a singing voice, it does not adapt to different singing synthesis conditions (e.g., different singing synthesis systems and their singer databases) or singing skill/style modifications. To deal with different conditions, VocaListener repeatedly updates singing synthesis parameters so that the synthesized singing can more closely mimic the user's singing. Moreover, VocaListener has functions to help modify the user's singing by correcting off-pitch phrases or changing vibrato. In an experimental evaluation under two different singing synthesis conditions, our system achieved synthesized singing that closely mimicked the user's singing.
VocaListener consists of three components, the VocaListener-front-end for singing analysis and synthesis, the VocaListener-core to estimate the parameters for singing synthesis, and the VocaListener-plus to adjust the singing skill/style of the synthesized singing.
Figure 1 shows an overview of the VocaListener system. The user's singing voice (i.e., target singing) and the lyrics are taken as the system input (Fig1. A). Using this input, the system automatically synchronizes the lyrics with the target singing to generate note-level score information, estimates the fundamental frequency (F0) and the power of the target singing, and detects vibrato sections that are used just for the VocaListener-plus (Fig1. B). Errors in the lyrics synchronization can be manually corrected through simple interaction. The system then iteratively estimates the parameters through the VocaListener-core, and synthesizes the singing voice (Fig1. C). The user can also adjust the singing skill/style (e.g., vibrato extent and F0 contour) through the VocaListener-plus.
This research utilized the RWC Music Database "RWC-MDB-G-2001" (Music Genre). In our current implementation, VocaListener estimates parameters for commercial singing synthesis software based on Yamaha's Vocaloid or Vocaloid2 (in Japanese) technology. For example, we use software named Hatsune Miku , Kagamine Rin , and Megurine Luka for synthesizing Japanese female singing.
We thank Jun Ogata (AIST), Takeshi Saitou (CREST/AIST), and
Hiromasa Fujihara (AIST) for their valuable discussions.
This research
was supported in part by CrestMuse, CREST, JST.